DEMONSTRATE achieves comparable or improved success rates to the chosen baseline models in simulation and has shown its applicability in real-world experiments:
Pipeline
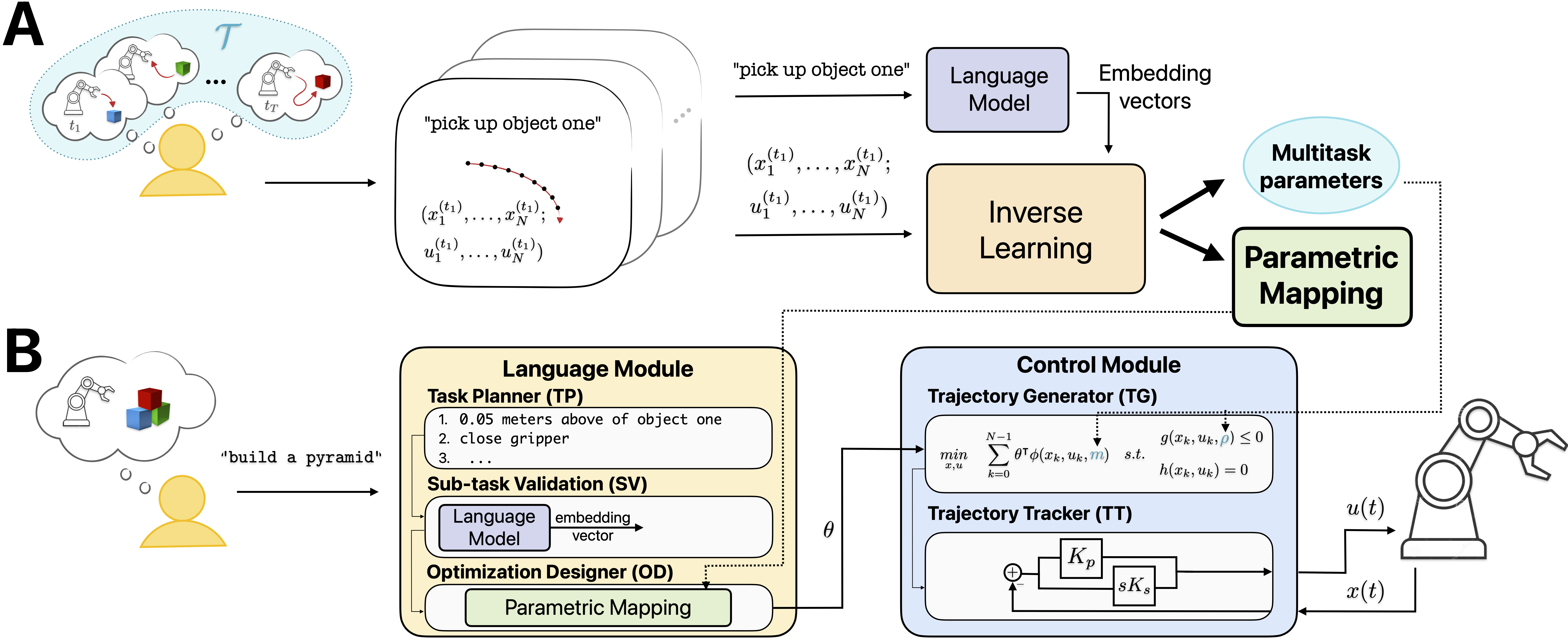
DEMONSTRATE’s architecture is based on a two-stage pipeline:
- A. Offline pipeline: A user provides sub-task descriptions together with trajectory demonstrations and an LLM is employed to compute the embedding vectors for the sub-task descriptions. The demonstrations and the embedding vectors are then used to learn (i) a parametric mapping from embedding to task vector, and (ii) the shared multitask parameters, both used in the online pipeline.
- B. Online pipeline: Architecture of the NARRATE pipeline, with an added Sub-task Validation Module and a modified Optimization Designer. A complex user command is initially passed to the Task Planner, dividing it into multiple sub-tasks and another LLM is used to find their embedding representations. After checking their similarity with the provided sub-task examples in the offline pipeline for sub-task validation, they are then fed into the parametric map to compute the feature vector used in the Trajectory Generator block.